Performs a cross-validated ANOVA (CV-ANOVA) test for OPLS models. The function compares residuals from a null model and a model using cross-validated predictive scores to assess the significance of the OPLS model.
Value
A data.frame containing:
SS- Sum of SquaresDF- Degrees of FreedomMS- Mean SquaresF_value- F statisticp_value- P-value from the F-test
Details
CV-ANOVA formally compares the fit of two linear models using the size of their residuals. The null model regresses the response on an intercept only: $$Y_i = \beta_0 + \epsilon_i$$ The full model includes the cross-validated predictive scores: $$Y_i = \beta_0 + \beta_1 t_{\text{pred},i} + \epsilon_i$$ Here, \(Y_i\) is the response for observation \(i\), \(t_{\text{pred},i}\) the cross-validated predictive score, and \(\epsilon_i\) are residuals. The residual sums of squares (SS) and degrees of freedom (DF) from both models are used to calculate an F-statistic and associated p-value to assess if the OPLS model significantly improves the fit.
Please note: larger sample sizes increase the power to detect true effects. With few samples, even strong models may not reach statistical significance.
References
Eriksson, L., et al. (2008). CV-ANOVA for significance testing of PLS and OPLS models. Journal of Chemometrics, 22(11-12), 594–600.
See also
Other NMR:
alignSegment(),
binning(),
get_idx(),
lw(),
matspec(),
noise.est(),
normErectic(),
read1d(),
read1d_raw(),
stocsy1d_metabom8-class,
storm()
Examples
data("covid")
X <- covid$X
an <- covid$an
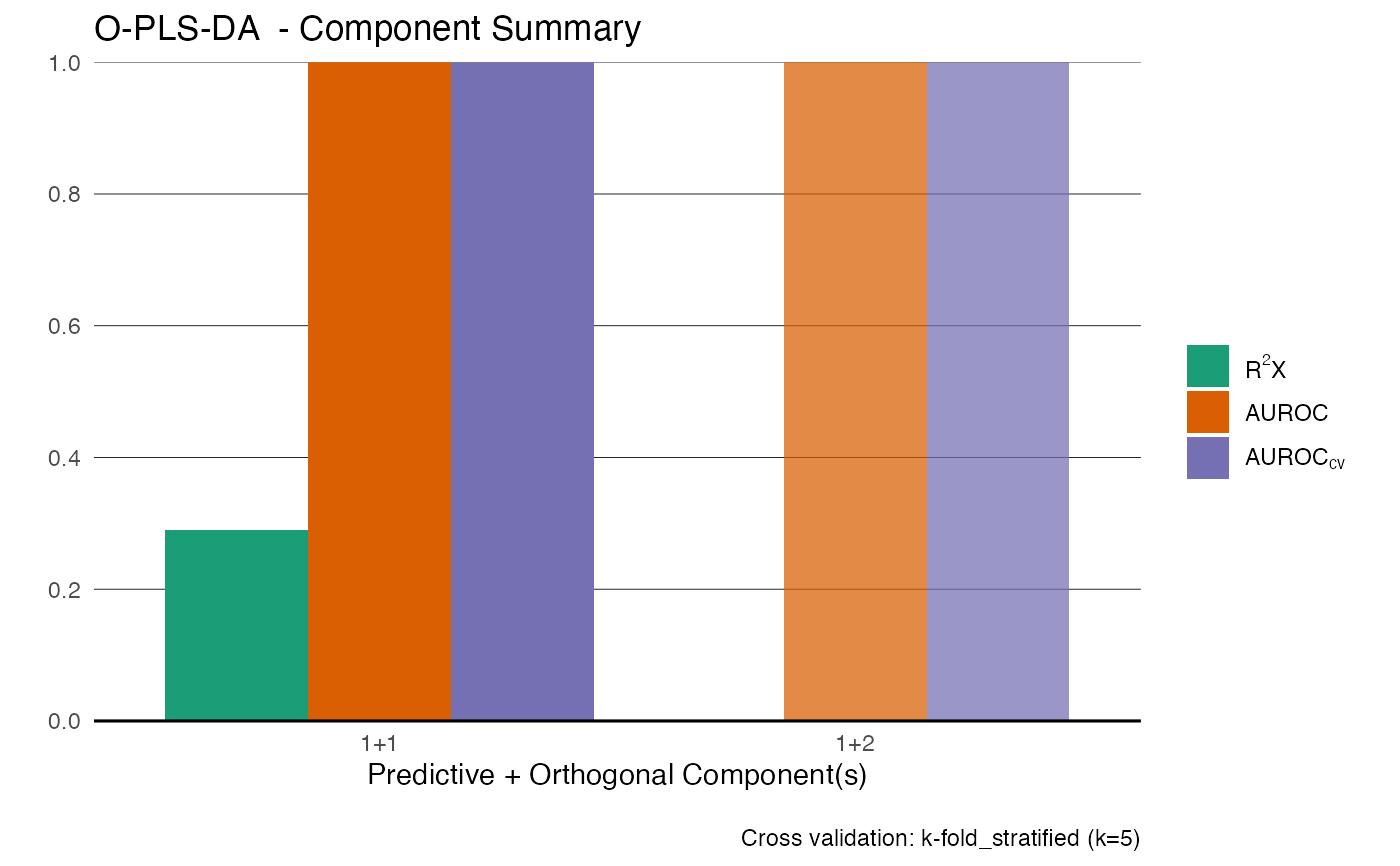
mod <- opls(X, an$type)
#> Performing discriminant analysis.
#> Reducing k to 5 due to small group size (min n = 5).
#> An O-PLS-DA model with 1 predictive and 1 orthogonal components was fitted.
 cvanova(mod)
#> SS DF MS F_value p_value
#> Total corrected 9.000000e+00 9 1.000000e+00 NA <NA>
#> Regression 3.609325e+00 4 9.023312e-01 NA <NA>
#> Residual 5.390675e+00 5 1.078135e+00 NA <NA>
#> RESULT <NA> NA <NA> 0.836937 5.560243e-01
# Internally, two linear models are fitted:
# Null model: lm(Y ~ 1)
# Full model: lm(Y ~ 1 + t_pred_cv)
#
# where Y is the response variable and t_pred_cv the cross-validated predictive scores.
cvanova(mod)
#> SS DF MS F_value p_value
#> Total corrected 9.000000e+00 9 1.000000e+00 NA <NA>
#> Regression 3.609325e+00 4 9.023312e-01 NA <NA>
#> Residual 5.390675e+00 5 1.078135e+00 NA <NA>
#> RESULT <NA> NA <NA> 0.836937 5.560243e-01
# Internally, two linear models are fitted:
# Null model: lm(Y ~ 1)
# Full model: lm(Y ~ 1 + t_pred_cv)
#
# where Y is the response variable and t_pred_cv the cross-validated predictive scores.